 Section
Navigation
Section
Navigation
7. Technical Aspects
:Fundamental
7.1 Anatomy of Internet
7.2 Telecommunications
7.3 Wireless systems
7.4 Client Computers
7.5 Mobile Devices
7.6 Operating Systems
7.7 Computer Programs
7.8 Security: Applications
7.9 Browsers
7.10 Business Intelligence Systems
7.11 Cloud Computing
7.12 Databases
7.13 DTP Programs
7.14 eBook Readers
7.15 eMail Services
7.16 Expert Systems
7.17 Graphics Programs
7.18 Internet TV
7.19 Music & Video
7.20 Really Simple Syndication
7.21 Rich Media
7.22 Search Engines
7.23 Spreadsheets
7.24 Video Conferencing
7.25 Word Processing
:Corporate Matters
7.26 Cluster Analysis
7.27 Neural Networks
7.28 Pricing Models
7.29 Realtime Systems
7.30 Regression Analysis
 7.29
Collective Intelligence in Realtime
7.29
Collective Intelligence in Realtime
Collective Intelligence is more widely employed than most Internet users
realize. 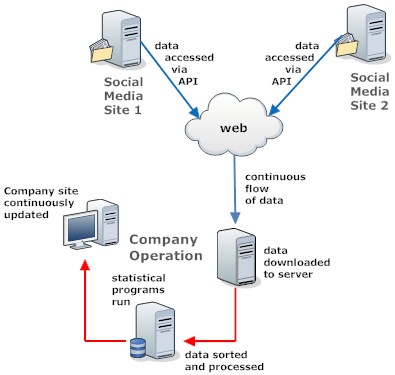
Netflix lets people choose movies to be sent to their homes, and makes recommendations based on what customers have previously rented. Google watches visitor behavior, and employs complex algorithms to produce its PageRank. Amazon analyzes previous purchases, and emails customers with new titles of interest. The Hollywood Stock Exchange lets you buy and sell stocks at a price accurately set by trading behavior. Digg facilitates the sharing of Internet content by the collective votes of its users. Del.icio.us is a successful social bookmarking service that allows you to tag, save, manage and share web pages from a centralized source. Etc. But these are only the most obvious examples. Behind the scenes, complex algorithms are constantly being employed to:
1. Detect patterns of fraud in credit card transactions by neural networks
and inductive logic.
2. Identify intruders in military installations by automatically analyzing
video footage.
3. Group customer demands in product design and advertising.
4. Predict demand in supply chains and so minimize inventories.
5. Pinpoint opportunities in stock markets worldwide.
6. Minimize threats by analyzing the increasing data that government
agencies hold on individuals.
How does this help the eretailer? In today's increasingly competitive
environment it's imperative that companies:
1. Identify their better customers: those worth courting with special
offers and products.
2. Ensure their goods and services are priced appropriately.
3. Discover and focus on their more profitable lines.
4. Anticipate customer reactions and have support staff properly prepared.
5. Make shopping a pleasant experience, treating each customer as a
valued individual.
6. Keep abreast of their competitors — automatically, without tedious
manual searches.
Implementation is highly technical, and this page only provides an introduction
to the theory, approaches and programming of specific instances.
Theory
What is collective intelligence, and does it really work?
A broad, straightforward definition: 'Collective intelligence is any intelligence that arises from, or is a capacity or characteristic of, groups and other collective living systems'. Tom Atlee and George Pór (2007) defined intelligence as the ability to interact successfully with one's world, especially in the face of challenge or change. Human intelligence involves gathering, formulating, modifying, and applying effective knowledge — often in the form of ideas, images, sensations, patterns of response and sense-making — a process we refer to with words like learning, problem solving, planning, envisioning, intuition, understanding, creativity, etc. Anyone trying to create effective groups, organizations, institutions, healthy communities and sustainable societies soon discovers that individual intelligence is an insufficient factor in their success.
That groups are better at prediction is shown by focus groups and the stock market. Neither is free of bias or sudden changes of heart, but both give a better snapshot of political and business sentiment than the single pundit — and explain why it's so difficult to 'beat the market'.
MIT's Center for Collective Intelligence (CCI) is building systems to solve complex problems like climate change, cancer treatment, and IQ assessment, where no one person or group can be conversant with all of the issues. CCI researchers are exploring collective prediction, building on popular Internet sites where people can buy and sell predictions about the outcome of elections, sporting events, etc. Such web sites, based on the collective wisdom of their users, have proven remarkably accurate.
Though experience has been mixed, many institutions and businesses are pouring considerable funds into this field, which speaks for its potential value. Innocentive, which consults with 160,000 scientists and engineers, offering large cash prizes for innovative solutions, claims that as of 2006, 30% of the problems posted have been solved. Sermo is an association of 70,000 US physicians enabling members to post questions to fellow experts, and Collective Intellect summarizes viewpoints in blogs and other web pages for applications in finance and marketing.
Example One: Video Hire: Making Recommendations
If someone's been shopping at your estore for a while, it's not difficult to build a customer profile. The classic case is books: Amazon notes previous interests and emails the customer with new titles of possible interest. The methodology is proprietary, but Amazon clearly note the customer details, email address, credit-worthiness, the patterns of consumer spend and the fields of interest, sending an email when the field of interest under which they classify all their products matches that of a valued customer. A snippet of code (SQL request) searches the customer and product databases for a match, extracts name, email and recommendation, calls a script to wrap them into an email, and off it does. Any programmer can tell you more.
Less simple are partial matches. Your video store customer may like action movies, but he doesn't like them all. He wants the best, especially those that have been well-reviewed by critics or sites whose remarks he generally agrees with. To make recommendations in this case you'll need data for 1. comparisons and 2. some statistics.
Data Sources
There's a surprising amount of data readily available if you know where to look. There are your own server logs, whose data you can download in comma-delimited text files. AdSense and most traffic analytical programs also let you download the data from their sites, often in Excel-compatible or text forms. Much more extensive is the data that can be accessed from social bookmarking services like Del.icio.us and specialist sites. To do so, however, you'll have to obtain an API (application programming interface) from ProgrammableWeb and other sources, and write scripts to use them — access the data, extract it, organize and analyze it: i.e. computer programming.
Statistics
Anyone who pursues research in the life and natural sciences (and increasingly a good many other careers) will be familiar with the various ways of sorting and analyzing data: correlation, multivariate analysis, time series, etc. The formulas involved are daunting, but their derivation is the concern of statisticians. What the researcher does require is:
1. A broad understanding of statistical approaches,
2. The background to know which statistical methods apply in which sorts
of problem dealing with what sorts of data,
3. How to acquire and use the various statistical packages now available
for computer use,
4. How to interpret the results sensibly. If the data is in real time
(i.e. obtained from their server logs as customer details come in, or
from third-party social sites) then the research will also need programming
skills to extract that information from web servers, obtain or write
computer code for statistical analysis (most are available in computer
language libraries), feed the data into the code, and use the results
properly.
If, like most eretailers, your math ended in high-school, you'll need to do the following:
1. Clearly formulate what you want to do with your site,
2 a. Acquire some basic statistical knowledge: college courses, Internet
sites or the local library, or
2 b. Read something like Toby Segaran's Programming
Collective Intelligence (which provides a simple approach to the
statistical concepts, data sources and much of the computer code in
Python), or
2 c. Consult the better marketing companies who will have in-house statistical
skills, and
3. Do a cost-benefit study of the work involved. Programming won't be
cheap, and you do need to quantify the competitive advantages. 'Let's
just try it and see', is feasible only for companies with a large R&D
budget.
Assessing Recommendation
You'll start by asking your customers to rate the movie they rent: say awful (-2), poor (-1), OK (0) good (1) or fantastic (2). In time you'll want to compare ratings between your individual customers, but at first you'll be reliant on the recommendations on third-part sites, i.e. on Yahoo My Movies, Criticker, WhattoRent, Clerkdogs and the like.
A. Linking Customer to Third-Party Recommendations
Your next step is to assess the recommendations on third-party sites. You will:
1. Select the titles of your most popular video hires,
2. Collect the scores of these titles on your site given by your regular
customers,
3. Find these titles on third-party sites and convert their recommendations
into your sort of score [ i.e. into awful (-2), poor (-1), OK (0) good
(1) or fantastic (2)],
4. Store details in a database.
4. By comparing scores, derive similarity weightings, customer to customer, film by film,
for customers on those sites and yours.
B. Rating the Recommendations
1. Now you could simply look at the similarity scores and match customers across sites. If Betty Lewis, your best customer, rates her video titles pretty much as the Criticker site does, Critiker's ratings for new films would apply to Betty too. You could use their hot ratings to select other films for her, and email her with titles as they become available.
2. But that's a little unreliable, as everyone has odd quirks. You need to 'average' the similarity weightings by considering several films in the same category and the ratings on similar sites. That 'averaging' will employ some clustering or nearest neighbor approach, and you'll need to use some filtering device to reduce the computational effort involved in comparing everything with everything else.
Details
No code or statistical reasoning is provided here, but readers can be assured that:
1. The statistical methods are well known: they are explained in books
and on Internet sites, with the necessary formulas given.
2. Most of the code, for extracting the information and deploying statistical
assessments, is provided in Python by Toby Segaran book (see below)
3. Code libraries exist for handling data and statistical analysis in
most computing languages: you don't have to reinvent the wheel by writing
your own.
4. A halfway house exists. Before plunging into programming you can
extract data and experiment using various statistical packages, some
free.
5. Data can be extracted automatically from third-party sites (and then
processed entirely by computer) by using a free API (application programming
interface), e.g. that supplied by Netflix.
Example Two: Travel Planning
In this fictitious example, you're a large travel company with dozens of tours starting every day in different parts of the world. Every day you've got to get the participants to the rendezvous points, arranging their flights in the cheapest and most convenient way for them. Yes, you can spend hours on the phone to carriers and booking clerks — and will probably have to anyway, since there's always someone who messes up the best-laid plans — but ideally, you'll want to automate the process as much as possible.
You need an optimizing algorithm, and will probably start by expressing all possibilities as some cost function, this being the air fare plus some monetary weighting for travel time, time spent waiting for connections, and the inconvenience of early morning flights. Then the methods open to you are:
1. Consecutive searching. You'll feed all the possible itineraries
into a database and devise a program that calculates the costs in every
case. Each possibility for every member of the tour party will have
to be compared with every possibility for every other member, and the
set of bookings chosen that minimizes the total party cost. With a large
party, the approach will involve hundreds or thousands of iterations
, and probably leave some hard cases (two early starts, a 6 hour wait
for someone else, etc.), but the principle is easily grasped. Practicable,
but not efficient with computer time.
2. Hill climbing. Here the program takes a random schedule and looks
at neighboring itineraries to find one that is cheaper. That schedule
is treated the same way, and so on, until no cheaper schedules are found.
To avoid being caught in a local situation unrepresentative of the whole,
you'll need to repeat the exercise several times, starting at a different
points randomly selected. Not so easily envisaged, but more efficient.
3. Simulated annealing. The process starts with a complete set
of itineraries chosen at random. Then one of member's itineraries is
changed and costs compared. If there's a reduction, then that change
is adopted, and another member's itinerary is changed. Iteration continues
until the algorithm will only accept better solutions, and finally the
best. Similar to 2, more iterative, but avoids getting stuck in a local
situation.
4. Genetic algorithms. You start by creating a set of random
itineraries called a current population, which is then costed. You then
create another population, called the next generation, and add the top
solutions of the current population to it. Next, you modify members
of next generation by one of two methods. The first is called mutation:
you simply modify one of the members of the next generation. The second
is called breeding: you take two of the best solutions and combine them
in some way. Then you repeat the process and another population is created,
again repeating the process for a fixed number of iterations, or until no more improvement
is obtained. The best solution (cheapest set of itineraries) is the
one chosen.
Code for all these algorithms can be found in programming libraries
and tutorials.
How do you get the airfares and schedules in the first place?
If you have an online booking service, then you'll have access to this flight information.
If not, you can use a vertical search engine like Kayak, accessing through an API (application programming interface: you sign up for a developer key with Kayak). Then you'll write some code, which in Python (other languages are possible, but Python has libraries of functions already written) that extracts the information you need to provide realtime solutions.
Which Statistical Approach?
Statistical approaches are not exclusive, and you'll often find yourself using several methods to unlock the significant details of the information you've collected. At least to start with, however, it may help to view problems in this way:
1. Have masses of data? Don't need to know the significant factors?
Use neural networks.
2. Have less data? Important to know the relevant factors? Use regression
analysis.
3. Need to distinguish groupings in a mass of data? Use cluster analysis.
4. Need to find the nearest representative? Use kNN analysis.
Resources
1. Statistics on the Web. Clavius
Web. Clay Helberg's useful listing of sites.
2. Pitfalls of Data Analysis by Clay Helberg. June 1995. Clavius
Web. June 1995.
3. Information Theory, Inference, and Learning Algorithms by
David MacKay. David
MacKay. September 2003.
4. Free Statistics. Free
Statistics. Good listing of open source and freeware statistics
packages.
5. Statistical Analysis Software Survey. LionHRTPub.
Useful tables if you're familiar with statistics packages.
6. Python
Resources in One Place. Codes for many applications.
7. Java
Programming Resources. Tutorials, compiler and resources.
8. CPAN. Comprehensive
Perl Archive Network.
9. Innocentive.
Offers a marketplace where 160,00 engineers and scientists cooperate
to solve problems.
10. YourEncore.
Offers a network of retired and veteran scientists and engineers providing
our clients with proven experience.
11. Statistics. Wikibooks.
Extensive sets of articles, not all complete.
 Questions
Questions
1. What is meant by realtime systems? How are programming expenses
justified?
2. Give three examples of realtime systems, and their commercial advantages.
3. You've been asked to design the logical system of realtime video
hire company. Describe the steps you would take.
4. You're presenting a consultant's plan for a realtime travel company
startup. What approaches are possible, and where would the company get
its realtime data from?
 Sources
and Further Reading
Sources
and Further Reading
1. Algorithms of the Intelligent Web by Haralambos
Marmanis and Dmitry Babenko. Manning Publications. June 2009. Specimen
code in Java.
2. Programming Collective Intelligence: Building Smart Web 2.0 Applications
by Toby Segaran. O'Reilly. August 2007. Includes specimen code in Python.
3. You're Leaving a Digital Trail. What About Privacy? by John
Markoff. NYT.
November 2008.. Article suggesting the numerous applications of CI.
4. Putting heads (and computers) together to solve global problems
by Anne Trafton. MIT.
January 2009.
5. Collective intelligence. Wikipedia.
With examples and a short listing of sites.
6. Handbook of Collective Intelligence. MIT.
Detailed, Wikipedia-like entry on MIT site, with good theory and examples.
7. Blog
of Collective Intelligence. George Pór's: many useful
posts by an expert.